
Mit dem Voranschreiten des Digitalisierungszeitalters geht eine immer größer werdende Menge an Daten einher. Dies eröffnet nicht nur viele Chancen, sondern bringt gleichzeitig auch wachsende Herausforderungen mit sich. Diese erfordern vor allem eines: Neue und fortschrittliche Technologien, die diese Datenmengen bewältigen können. Im Zuge dieser Entwicklung wird dem Einsatz von Machine Learning in den letzten Jahren große Aufmerksamkeit zuteil. Insbesondere ist dies einem bestimmten Teilbereich zu verdanken – dem Deep Learning.
Einfach gesagt wird beim Deep Learning zuerst eine künstliche Intelligenz trainiert, indem sowohl Fragestellungen als auch die zugehörigen Lösungen eines spezifizierten Problems in das System eingespeist werden. Allgemein gilt hierbei, dass eine größere Menge an dazu verwendeten Daten zu einer besser trainierten Intelligenz führt. Nicht selten werden zu diesem Zweck riesige Datenmengen ausgewertet. Anschließend ist diese Intelligenz in der Lage, Probleme derselben Art eigenständig zu lösen.
Eine Abstraktion des menschlichen Gehirns
Aber was genau hat das Ganze eigentlich mit künstlicher Intelligenz zu tun? Das Konstrukt, mit dem hierbei gearbeitet wird, ist ein neuronales Netz – gewissermaßen ein auf seine wesentlichen Elemente reduzierter Nachbau des Gehirns. Wie im Gehirn auch, sind die Grundeinheiten hierbei die Neuronen. [1]
Aber ganz so biologisch wie die Begrifflichkeit es vermuten lässt, ist es dann doch nicht. Im Prinzip steckt hinter der kompletten Logik neuronaler Netze eine Vielzahl an umfangreichen Berechnungsmethoden aus der Linearen Algebra, die früher – ohne die Kapazität an heute zur Verfügung stehender Rechenleistung – nicht zu bewerkstelligen waren. Deshalb hatten beispielsweise die „Support Vector Machines“ (kurz: SVM) lange Zeit den Vorzug bei der Verarbeitung von Informationen erhalten.
Die Neuronen sind in einer beliebigen Anzahl von verschiedenen Schichten oder auch Layern organisiert. Dabei steht jedes Neuron mit den Neuronen der vorherigen Schicht und der nachfolgenden Schicht in Verbindung. Doch worin unterscheiden sich die neuronalen Netze, wenn jedes Netzwerk auf die gleiche Art und Weise konstruiert wird? Die Antwort darauf verbirgt sich in der Ausprägungsstärke der jeweiligen Verbindung. So sind diese Verbindungen keineswegs gleichwertig, sondern zeichnen sich erst durch das ihnen zugewiesene Gewicht aus.
Lernen durch umfangreiche mathematische Berechnungen
Es wird zwischen drei verschiedenen Arten von Layern unterschieden. Im Input-Layer sind die zugewiesenen Neuronen die Träger der ursprünglichen – also der an das Netz übergebenden – Informationen. Somit stellt er die Ausgangsbasis für alle im neuronalen Netz praktizierten Berechnungen dar. Nach außen hin nichts weiter als eine Blackbox, stellt der darum so bezeichnete Hidden-Layer das Zentrum des Netzes dar.
Genauer gesagt sogar die Hidden-Layer, da sie im Gegensatz zu den anderen beiden Layer-Typen, mehr als einmal auftreten können. Diese Eigenschaft in Kombination mit der Tatsache, dass sie den Mittelpunkt der umfangreichen mathematischen Berechnungen darstellen, ist der Grund dafür, warum man neuronale Netze mit dem Begriff „DEEP Learning“ gleichsetzt. [2] Als Pendant zum Input-Layer steht der Output-Layer. Von den Neuronen dieser Schicht wird letztendlich das zu Ende kalkulierte Ergebnis repräsentiert.
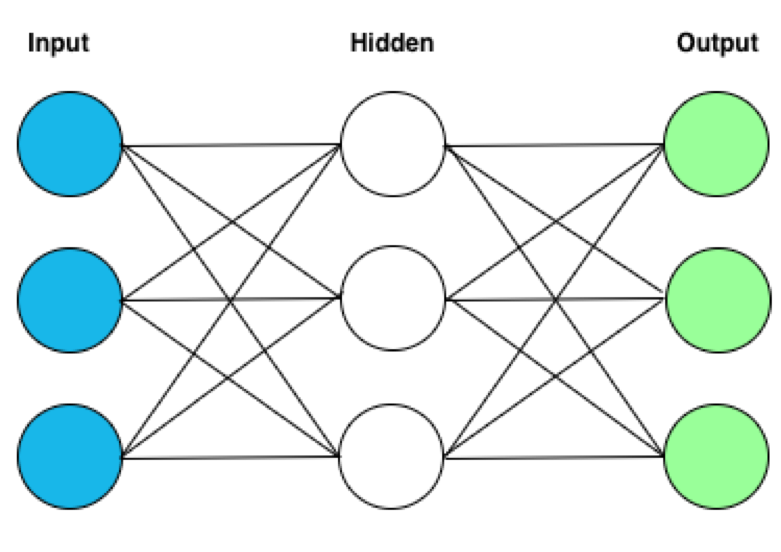
Liegen einem nun also Daten vor, die gleichzeitig ein Ergebnis – oder um in der Fachsprache zu bleiben – ein Label besitzen, sind auf diese Weise Input- und Output-Layer definiert. Das Netz kann trainiert werden. Das Verfahren, das hierbei zum Einsatz kommt und sich hinter dem Lernen verbirgt, nennt man Backpropagation. Übersetzt bedeutet dies soviel wie Fehlerrückführung. Kurz gesagt wird hierbei hinsichtlich der eingegebenen Informationen ein Ergebnis berechnet und schließlich mit dem tatsächlichen Resultat verglichen. Mit Hilfe dieses Vergleichs kommt es im folgenden Schritt zur Gewichtsanpassung der Neuronenverbindungen. Diese Schritte werden für jede Datenreihe des Trainingsdatensatzes durchgeführt.
Einsatzmöglichkeiten in allen Bereichen
Die Zahl der vielfältigen Anwendungsmöglichkeiten dieser Techniken wächst stetig in den unterschiedlichsten Bereichen. Aber besonders der Einsatz im Themengebiet des autonomen Fahrens [3] ist derzeit in aller Munde. Das Schlagwort lautet dabei Echtzeit-Objekterkennung und das im Kontext des Straßenverkehrs. Innerhalb von Millisekunden müssen hierbei die richtigen Entscheidungen getroffen werden. Eine einzige falsche Entscheidung, wie ein zu spätes Bremsen oder ein falsches Ausweichmanöver, kann verheerende Folgen nach sich ziehen – bis hin zur Auslöschung eines oder mehrerer Menschenleben. Wenn man so will, entscheidet eine Maschine beziehungsweise deren antrainierte Intelligenz also über Leben und Tod.
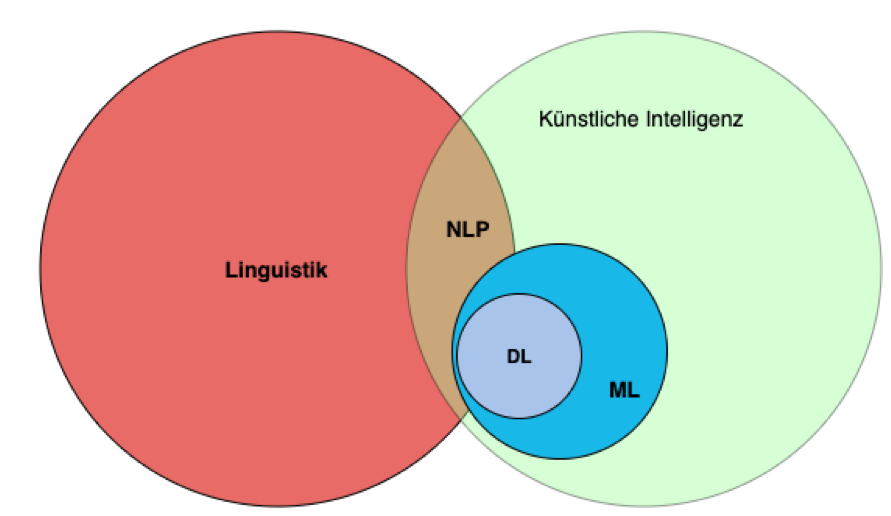
Aber auch bei weniger populären Themen, wie nicht zuletzt die Bild- und Spracherkennung, nimmt die angestrebte Automatisierung eine immer zentralere Rolle ein. Natural Language Processing ist gewissermaßen die Symbiose aus den Bereichen Linguistik und künstlicher Intelligenz. [4] Neben der Spracherkennung spielt dieser Bereich zum Beispiel noch bei Themen wie Spam-Filter oder auch der Klassifizierung von Text eine entscheidende Rolle. Um ein Beispiel zu nennen, ist es mit Hilfe von NLP (Abkürzung für Natural Language Processing) unter anderem möglich, anhand eines News-Textes diesen einer Kategorie (wie Sport, Politik etc.) zuzuweisen.
Web-Shops benötigen den Fortschritt
Auch im E-Commerce Bereich kann man von NLP in großem Maße profitieren. Die zentralen Elemente eines jeden Web-Shops sind die Produkte, die dieser anbietet. Analog zur Einordnung eines News-Textes in eine bestimmte Sparte, steht hierbei die Klassifizierung von Produkten in ihre entsprechenden Kategorien – gewissermaßen in virtuellen Regalen. Je nach Größe des Shops ist dies ohne Techniken des maschinellen Lernens mit extensiver manueller Arbeit verbunden.
Um eine beständige erfolgreiche Kundenakquisition zu gewährleisten, muss sich das Angebot eines fortschrittlichen Online-Shops ständig ändern. Alte Produkte werden aus dem Sortiment entfernt und neue Produkte werden eingepflegt und beworben. Es handelt sich hierbei also um eine immer wiederkehrende, unerlässliche Arbeit – die ideale Einsatzmöglichkeit für künstliche Intelligenz.
Doch ganz so einfach ist es leider nicht. So trivial im ersten Moment die Einordnung von Produkten in Kategorien auch erscheinen mag, lässt dies komplett die Tatsache außer Acht, dass im menschlichen Gehirn bei dieser Aufgabe in Sekundenbruchteilen viele Entscheidungsprozesse stattfinden, die es ermöglichen, das Produkt adäquat in die entsprechende Kategorie einordnen zu können.
Hinzu kommt, dass diese Entscheidungen zum Großteil auf bereits (jahrelang) erworbenen Erfahrungen beruhen. Das impliziert, dass für diese Problemstellung keine einfache technische Lösung existiert. Dementsprechend ist kein simpler Algorithmus denkbar, der in der Lage wäre, diese Aufgabe zufriedenstellend zu bewerkstelligen. Die Idee ist, dass man genau diese angesprochene Erfahrung nutzt und diese dem neuronalen Netz, in Form von exorbitanten Dokumentmengen, versucht mitzugeben.
Text vergleichbar machen
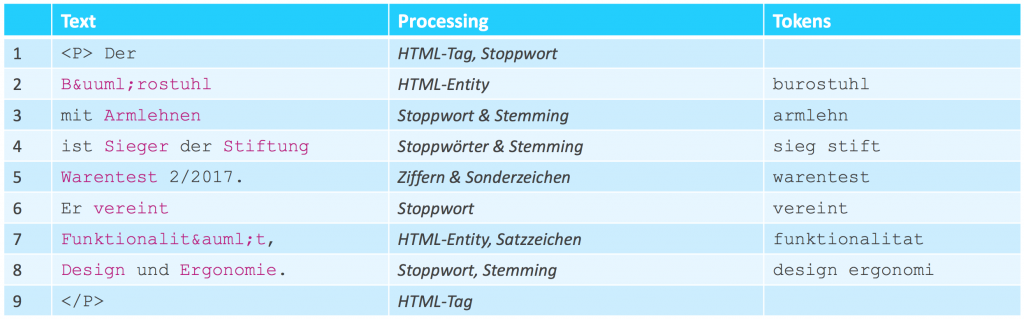
Das Natural Language Processing ist ein vielschichtiger Prozess, dessen detaillierte Erläuterung den Rahmen dieses Blogartikels sprengen würde. Deshalb wird sich hier auf ein paar zentral ausgewählte Konzepte bezogen. Im Grunde steht am Anfang dieses Prozesses das sogenannte Pre-Processing des Textes. Hierbei wird der Originaltext oder auch Rohtext, wie er beispielsweise in Produktbeschreibungen zu finden ist, in seine Bestandteile zerlegt und anschließend normalisiert. Ziel des Ganzen ist es, vergleichbare Textobjekte zu erschaffen, die auf die einfachste Form miteinander verglichen werden können. Diese Bestandteile nennt man Token.
Im ersten Schritt spielt sich der Prozess hierbei auf Zeichenebene ab. Das heißt, es werden beispielsweise einzelne HTML-Sonderzeichen, die gerade in Verbindung mit dem Web häufige Verwendung finden, ausgetauscht. Wichtig ist hierbei in jedem Fall die Reihenfolge der Einzelschritte zu beachten, da beispielsweise „ “ eine HTML-Kodierung für das Leerzeichen ist und Einfluss auf den nachfolgenden Schritt haben kann.
Hier wird der Text mit Hilfe eines sogenannten „Tokenizers“ an einer bestimmten Stelle aufgespaltet. Das Ergebnis sind in der Regel einzelne Wörter bis hin zu kürzeren Phrasen. Äußerst beliebt ist hierbei die Vorgehensweise, die Aufspaltung anhand der Leerzeichen des Textes (Whitespace-Tokenizer) durchzuführen. [5] Nach der Zerlegung sind die Token definiert. Während es durchaus möglich ist, mehrere Zeichen- oder Wortfilter auf die Token anzuwenden, so ist von der gleichzeitigen Nutzung mehrerer Tokenizer abzuraten.
Da die einzelnen Token Byte für Byte verglichen werden, wird selbst zwischen Groß- und Kleinbuchstaben unterschieden. Deshalb ist es üblich, den kompletten Text in Kleinbuchstaben zu konvertieren. Eine Methode, die etwas fortgeschrittener ist, ist das sogenannte „Stemming“. Hierbei wird jedes Wort auf seinen Wortstamm zurückgeführt. Da die Bildung des Wortstammes erheblich von der zu Grunde liegenden Sprache abhängt, ist dies ein etwas aufwendigerer Prozess. Allerdings können vorgefertigte Bibliotheken hierbei Abhilfe schaffen.
Dokumente im Mittelpunkt der Analyse
Auch wenn man den Text in seine rudimentären Wortbestandteile zerlegt, so müssen die dabei resultierenden Token am Ende wieder zu einer Einheit zusammengefügt werden. Egal ob es sich hierbei um literarische Werke oder zu verkaufenden Produkten handelt, man bezeichnet das Ergebnis des Zusammenführens als Dokument. Dokumente, die als Trainingsdaten verwendet werden können, besitzen außerdem noch ein Label, das bereits das richtige „Ergebnis“ (für das neuronale Netz), wie z.B. eine Produktkategorie, enthält.
Bevor dieser Zusammenbau erfolgt, ist es ratsam, noch weitere Filtermethoden in Betracht zu ziehen. So ist beispielsweise eine oftmals eingesetzte Technik das Herausfiltern von Wörtern, die nicht zur tatsächlichen Definition des Dokumentes beitragen, weil sie Bestandteil einer Vielzahl von Dokumenten sind. Zusammengefasst werden sie unter dem Begriff „Stopp-Wörter“. Zur Vollständigkeit in diesem Bereich sei zu sagen, dass auch weniger drastische Methoden zum Einsatz kommen können. Sie treffen nicht nur eine Entscheidung darüber, ob ein Wort erhalten bleibt oder entfernt wird, sondern weisen den einzelnen Wörtern eine explizite Gewichtung zu, die die Bedeutung des Ausdrucks innerhalb des Dokuments sowie innerhalb aller Dokumente beschreibt. In Online-Suchsystemen wie Elasticsearch [6] und Solr [7] wird diese Methode (TF-IDF oder BM25) angewandt [8].
Training und Test des neuronalen Netzes
Doch egal wie diese Token gebildet werden, sie landen alle im neuronalen Netz. Ausgehend von einem anfänglichen Datensatz mit einer ausreichend großen Anzahl an Dokumenten – in der Linguistik auch als Dokumentkorpus bezeichnet – ist es nun üblich, den Datensatz zu zweizuteilen. Der erste Teil enthält 80% der Dokumente und dient zum Training des neuronalen Netzes. Die fertig konstruierten Dokumente samt dem dokumentspezifischen Label werden eingespeist.
Ist das neuronale Netz nun fertig trainiert, so kann dieses durch den zweiten Teil des anfänglichen Datensatzes, der aus den restlichen 20% der Dokumentmenge besteht, getestet werden. Die tokenisierten Dokumente werden hierzu in das neuronale Netz infiltriert, um mit Hilfe des „antrainierten Wissens“ eine Kategorieprognose abzugeben. Es ist nun möglich eine Statistik aufzustellen, bei wie vielen Dokumenten die Prognose mit dem im Label enthaltenen Ergebnis übereinstimmt.
Zur Erlangung statistischer Sicherheit wird der Schritt der zufälligen Teilung des ursprünglichen Dokumentkorpus mehrmals durchgeführt. Es ergibt sich zum Schluss ein prozentualer Mittelwert, der Aufschluss über die Zuordnungswahrscheinlichkeit gibt. Hierbei muss berücksichtigt werden, dass sich dieser Wert lediglich auf die im Dokumentkorpus enthaltenen Dokumente bezieht. Dieser muss bei externen Dokumenten, die möglicherweise sogar aus einer anderen Quelle stammen, nicht in Gänze übereinstimmen. Zu erwähnen sei hierbei zum Beispiel der Effekt des Overfittings, der ein zu starr trainiertes Netz beschreibt [9].
Der Weg ist das Ziel … ein kontinuierlicher Prozess
Erfolgreich trainiert kann das neuronale Netz zum Einsatz kommen. Es können Dokumente in das Netz eingespeist werden, für die mit Hilfe der im Inneren befindlichen Gewichtungsmatrizen ein entsprechendes Ergebnis berechnet werden kann. Durch anschließende Klassifizierung kann dem Dokument eine Kategorie zugeordnet werden. Von nun an können neue, nicht kategorisierte Produkte, dank des neuronalen Netzes in den bestehenden Web-Shop einsortiert werden. Der manuelle Aufwand reduziert sich auf ein Minimum und besteht im Wesentlichen darin, die errechneten Ergebnisse stichprobenartig zu überprüfen. Bei nicht zufriedenstellenden Ergebnissen kann das Netz an verschiedenen Stellen modifiziert werden. Doch die eigentliche Stärke zeigt sich erst, indem das Netz durch neue Dokumente fortwährend weiter trainiert werden kann. Denn genau das macht eine (künstliche) Intelligenz aus: Sie ist immer in der Lage, weitere Informationen zu verarbeiten, um stetig dazuzulernen und den Fehlerquotienten zu minimieren.
Quellen
[1] C. N. Nguyen and O. Zeigermann, Machine Learning–kurz & gut: Eine Einführung mit Python, Pandas und Scikit-Learn. O’Reilly, 2018.
[2] F. Chollet, Deep Learning mit Python und Keras: Das Praxis-Handbuch vom Entwickler der Keras-Bibliothek. MITP-Verlags GmbH & Co. KG, 2018.
[3] B. Huval et al., “An empirical evaluation of deep learning on highway driving,” arXiv Prepr. arXiv1504.01716, 2015.
[4] J. Hirschberg and C. D. Manning, “Advances in natural language processing,” Science (80-. )., vol. 349, no. 6245, pp. 261–266, 2015.
[5] G. S. Ingersoll, T. S. Morton, and A. L. Farris, Taming text: how to find, organize, and manipulate it. Manning Publications Co., 2013.
[6] “Elasticsearch Web Page.” [Online]. Available: https://www.elastic.co/de/.
[7] “Apache Solr Web Page.” [Online]. Available: https://lucene.apache.org/solr/.
[8] D. Turnbull and J. Berryman, “Relevant search: with applications for Solr and Elasticsearch,” Manning Publications Co., 2016, pp. 67–69.
[9] J. Lever, M. Krzywinski, and N. Altman, “Points of significance: model selection and overfitting.” Nature Publishing Group, 2016.



{kind=link}