
Ein kurzer Überblick über Apache PredictionIO
Mit PredictionIO stellt Apache einen Open-Source-Server für Anwendungen im Bereich Machine Learning vor. PredictionIO baut auf einem modernen Opensource Stack auf und erlaubt sowohl Entwicklern als auch Benutzern aus dem Bereich Data Science die Erstellung von verschiedenen Anwendungen für Vorhersageanalysen – in der Fachsprache als Predictive Analytics bezeichnet – unter Einbeziehung von Machine Learning. Einen großen Vorteil bieten dabei die bereits vordefinierten zur Verfügung stehenden Templates, da somit ein schnelles Erstellen und Bereitstellen diverser Webservices ermöglicht wird. In der Praxis ergeben sich damit vielfältige Einsatzmöglichkeiten.
Die wichtigsten Funktionen von PredictionIO
PredictionIO kann als vollwertiger Machine Learning Stack im Bundle mit Apache Spark, MLlib oder Akka HTTP sowie Elasticsearch installiert werden. Die Vorteile sind hierbei vielschichtig und erstrecken sich u.a. von der einfachen Verwaltung der für das Machine Learning erforderlichen Infrastruktur bis hin zu einer flexiblen Skalierung.
Die zur Verfügung stehenden Templates beinhalten bereits sogenannte „Engines“. Hinter diesem Begriff verbergen sich im Grunde verschiedenste Machine Learning Algorithmen, die weiter angepasst und feinjustiert werden können, um die optimalen Ergebnisse in Hinblick auf Predictive Analytics erzielen zu können. Anschließend kann das Gesamtpaket als Webservice zur Verfügung gestellt werden. Dabei ist es auch möglich, dass mehrere Engines zum Einsatz kommen, die wiederum verschiedene Algorithmen repräsentieren und über einen Event Server koordiniert werden. Anfragen an den Webservice können hierbei in Echtzeit beantwortet werden.
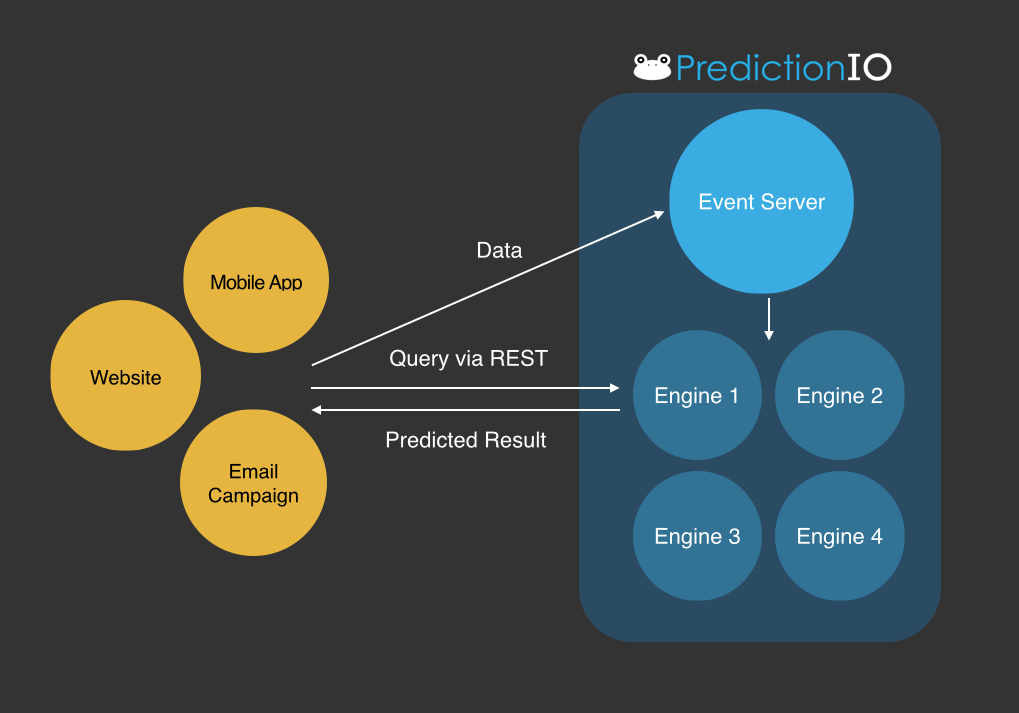
(Quelle: https://predictionio.apache.org/start/)
Die Ergebnisse werden durch die Trainingsdauer beeinflusst
Das Herzstück von PredictionIO ist der Einsatz von ML-Modellen. Deren Fähigkeiten hängen davon ab, wie intensiv der Anwender sein Modell trainiert. Welche Trainingsdauer erforderlich ist, um verwertbare Ergebnisse zu erhalten, hängt vom Algorithmus, den vorhandenen Daten und der damit verbundenen Datenqualität und der damit verbundenen Aufgabe ab. Häufig genügen bereits wenige Minuten bis wenige Stunden, um ein Modell auf einen guten Trainingsstand zu bringen. Die Aussagekraft und die Genauigkeit der Algorithmen-Ergebnisse von PredictionIO ist also unmittelbar mit der Zeit verflochten, die ein Anwender in das Training investiert.
Vorgefertigte Empfehlungssysteme
Wie bereits oben kurz angeschnitten ist es möglich, die Templates und die damit verbundenen Algorithmen den Wünschen und Bedürfnissen anzupassen und so innerhalb kürzester Zeit zu einer lauffähigen Lösung zu gelangen.
Bei Empfehlungssystemen (Recommendation Engines) ist es eine bewährte Methode, Nutzer mit einem ähnlichen Verhalten ausfindig zu machen, um anschließend mit den ermittelten Verhaltensmustern das Verhalten der anderen Person zu prognostizieren. Diese Methode bzw. der Algorithmus der dieser Methode zu Grunde liegt, ist auch unter dem Namen Collaborative Filtering bekannt. Dieser Algorithmus ist in einigen Templates bereits in Gestalt von Sparks Machine Learning Bibliothek integriert. Spark ist ein leistungsfähiges Framework für Cluster-Computing und bietet mit MLlib eine umfangreiche Funktionsbibliothek an, mit der sich häufig verwendete Machine-Learning-Algorithmen in den verteilten Systemen verfügbar machen lassen.
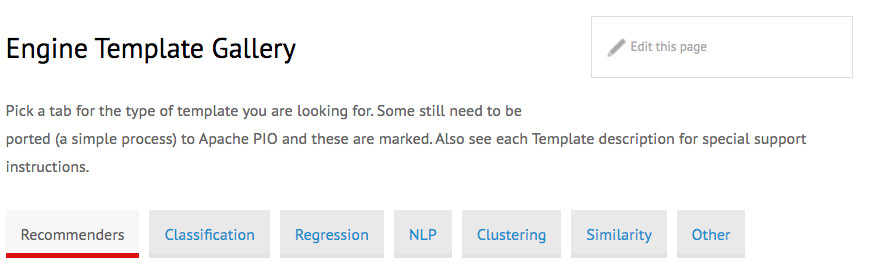
(Quelle: https://predictionio.apache.org/gallery/template-gallery/)
Mit der Engine Template Gallery hat der Nutzer Zugriff auf eine praktische Suchfunktion für Templates. Hier stehen eine Vielzahl von nützlichen Templates sortiert nach Kategorien zur Verfügung und der Nutzer erhält Empfehlungen, welche Templates für ihn besonders nützlich sein könnten. Häufig sind die Templates dabei nach Einsatzgebiet sortiert. Dazu gehören zum Beispiel Templates für Anwendungen im E-Commerce wie die Engine für Empfehlungssysteme. Den Nutzern eines E-Commerce-Shops lassen sich damit Vorschläge unterbreiten, welche Produkte für ihn besonders interessant sein könnten. So ist es beispielsweise möglich, nicht mehr vorrätige Produkte von den Vorschlägen auszuschließen und die Ergebnisse davon abhängig zu machen, ob der Kunde sich gerade registriert hat oder bereits länger im Shop einkauft. Bei länger bestehenden Kundebeziehungen basieren die Vorschläge auf den bisherigen Käufen. Bei einem neuen Konto ist es hingegen möglich, allgemein beliebte Produkte vorzuschlagen. Das Template ist soweit vorkonfiguriert, dass ein produktiver Einsatz der Engine im E-Commerce-Bereich schnell möglich ist.
Templates für Natural Language Processing
Ein weiteres großes Thema in Hinblick auf Machine Learning bietet die Verarbeitung und Auswertung der natürlichen Sprache. Es ist hierbei gewissermaßen das Ziel, dass der Computer den Sinn der menschlichen Sprache im ersten Schritt erfassen kann und im nächsten Schritt die Ergebnisse zur Lösung weiterer komplexer Probleme einbeziehen kann. Hinter dieser Verarbeitung verbirgt sich der stetig an Popularität zunehmende Begriff Natural Language Processing (kurz NLP).
Viele Anwendungen im Bereich des Maschinellen Lernens sind heute auf die Verarbeitung von Sprache angewiesen, daher bietet PredictionIO mit OpenNLP eine Opensource Bibliothek für die Verarbeitung von Daten im Bereich von Natural Language Processing an. Die plattformunabhängig einsetzbare Bibliothek ermöglicht die Umsetzung von vielfältigen Anwendungen, bei denen es auf Spracherkennung ankommt, die Erkennung von Sätzen oder die Zerlegung von Zeichenfolgen in Token (siehe dazu auch: https://blog.neozo.de/fortschrittliche-produktkategorisierung-in-web-shops-mittels-kuenstlicher-intelligenz/). Die Vielfalt der Templates in diesem Bereich ist besonders groß und daher ist in den meisten Templates die Bibliothek OpenNLP bereits vollständig integriert.
Es stehen zum Beispiel Templates für den Vergleich von Texten auf Ähnlichkeiten hin bereit. Hierfür kommen mächtige Algorithmen wie etwa Word2Vec zum Einsatz. Andere Templates dienen der allgemeinen Klassifizierung von Texten oder lassen sich dafür einsetzen, die Stimmung eines Textes einzuschätzen. Letztere Templates sind nützlich, um Sätze mit einer negativen Einfärbung oder einer positiven Stimmung zu erkennen (auch bekannt unter dem Begriff Sentiment-Analyse).
Templates für das Clustering
Eine wichtige Bedeutung im Rahmen der Predictive Analytics spielt das sogenannte Clustering. Dabei erfolgt eine Unterteilung von Datensätzen in kleinere Teilmengen mit Inhalten hoher Ähnlichkeit. Auch hierfür bietet PredictionIO passende Templates an. Die Templates sind dafür mit verschiedenen Algorithmen ausgestattet, die die Clustering-Aufgaben übernehmen. Dazu gehören weitverbreitete Algorithmen wie K-Means oder Latent Dirichlet.
Zu den typischen Aufgaben im Zusammenhang mit Clustering gehört das Topic Labeling. Hierbei gilt es für verschiedene Inhalte mit entsprechender Ähnlichkeit automatisch passende Beschreibungen und Überschriften zu finden. Bei der Analyse von Texten ist hierbei die Erfassung der Worthäufigkeiten und die Verteilung von bestimmten Begriffen eine zentrale Funktion. Einige Templates greifen für ihre Analyse auf Wikipedia als Wissensdatenbank zurück.
Der Nutzer des Webservices muss nichts weiter tun, als seinen Rohtext in eine Maske einzugeben. Nach der erfolgten Analyse erhält er dann die automatisch erstellten Label zurück. Das Topic Labeling ist nützlich, um Inhalte zu strukturieren und für die weitere Nutzung besser verwertbar zu machen. Viele weitere Templates kümmern sich um ähnliche Aufgaben im Bereich der Klassifikation.
Templates für die Regressions-Analyse
PredictionIO bietet auch für die Regressionsanalyse verschiedene Templates an. Bei dieser Vorhersagetechnik untersucht das Machine Learning Modell selbstständig den Zusammenhang zwischen einer vorherzusagenden Größe und einer erklärenden Variable. Ein möglicher Anwendungsfall ist die Analyse des Zusammenhangs zwischen der Fahrweise von Autobesitzern und der Anzahl der Verkehrsunfälle. Passende Templates für eine Vielzahl von Regressionsanalysefällen stehen über die Engine Template Gallery auf der Webseite von PredictionIO zur Verfügung.
Für Unternehmen stellen sich häufig Fragen danach, wie lange ein Kunde mit dem Unternehmen verbunden bleibt und wann zu erwarten ist, dass sich die Kundenbeziehung wieder löst. Für diese Verweildaueranalyse bietet PredictionIO passende Templates mit Algorithmen für die Ereigniszeitanalyse (Survival Regression) an. Denkbar ist zum Beispiel die Erstellung von Kundenprofilen anhand derer sich einschätzen lässt, wie lange der Kunde dem Unternehmen noch erhalten bleibt. Ebenfalls möglich ist eine Einschätzung des Kundenwerts über die zu erwartende Verweildauer hinweg. Der Lebenszeitwert (Lifetime Value Prediction) dient dann als Grundlage für die Entscheidung, welche Kunden das Unternehmen ansprechen soll.
Im Rahmen der Regressions-Analyse ergeben sich viele weitere interessante Anwendungsfälle. Verfügbar sind zum Beispiel Templates für die Vorhersage des zu erwartenden Energieverbrauchs oder für die Vorhersage der Preisentwicklung bei Häusern. Mit PredictionIO ist es einfach, Anwendern diese leistungsfähigen Vorhersageinstrumente im Rahmen eines Webservices zur Verfügung zu stellen.
Die Systemarchitektur im Überblick
Der Anwender der durch PredictionIO bereitgestellten Dienste sieht nur die Ergebnisse, die das System als Antwort auf seine Dateneingaben zurücksendet. Im Hintergrund arbeiten jedoch verschiedene Server, die die Verarbeitung der Daten und die Generierung der Vorhersagen steuern. Der Benutzer kommuniziert dabei nur mit dem eigentlichen Webserver. Dieser wiederum kommuniziert zum einen mit einem Eventserver, dem die Datenbank Apache HBase untersteht und dessen Aufgabe ist, die Events (wie zum Beispiel verschiedenste Arten von Nutzeraktionen) in dieser zu speichern. Zum anderen kommuniziert der Webserver mit dem sogenannten Prediction Server, indem er Anfragen an den Server sendet und als Antwort die entsprechenden Vorhersagen von diesem zurückgesendet bekommt. Damit letzterer Server überhaupt in der Lage ist, die entsprechenden Vorhersage zu treffen, bedarf es allerdings noch eines Zwischenschritts, der im Hintergrund abläuft.
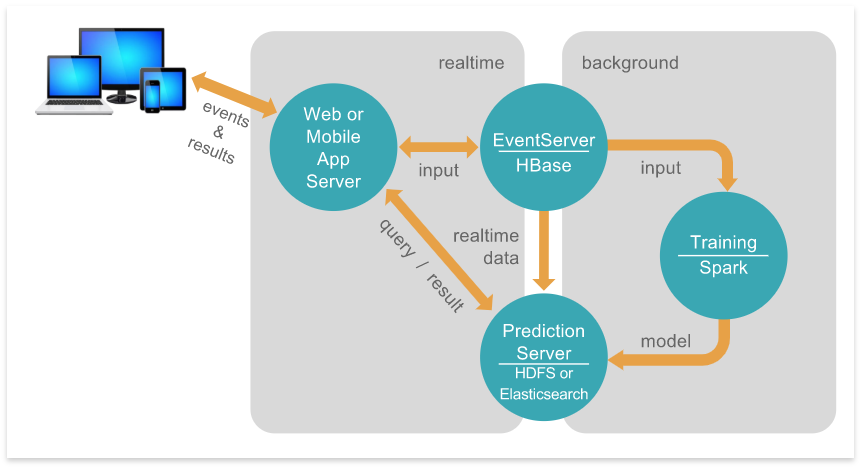
(Quelle: https://predictionio.apache.org/system/)
So kommuniziert der Eventserver mit einem weiteren Server im Hintergrund, der die gesammelten Daten entgegennimmt und daraus ein Machine Learning Modell trainiert. Dank Apache Spark ist es möglich, sehr große Mengen an Trainingsdaten in annehmbarer Zeit zu verarbeiten. Das fertig trainierte Modell wird dann wiederum an den Prediction Server weitergereicht, damit dieser in der Lage ist in Echtzeit die Anfragen der Benutzer zu beantworten. Der Trainingsprozess kann kontinuierlich erfolgen, da er separat erfolgt und somit kann das Modell stetig an Genauigkeit gewinnen und immer bessere Vorhersagen liefern.
Die Technologie, die beim Prediction Server zum Einsatz kommt, ist in der Regel HDFS. Das Hadoop Distributed File System bietet über einen Hadoop-Cluster einen hochperformanten Zugriff auf die benötigten Daten. Die Speicherung der Daten erfolgt also verteilt auf alle am Cluster beteiligten Maschinen. Dieses Dateisystem findet weite Verbreitung bei der Bewältigung von Aufgaben im BigData-Umfeld. Hier erfolgt zum Beispiel auch die Speicherung der als Templates vorliegenden Modelle. Außerdem ist das Dateisystem verantwortlich für den Batch-Import von Daten in PredictionIO.
Integration in bestehende Anwendungen
Eine der wesentlichen Stärken von PredictionIO ist die einfache Bereitstellung der Modelle für die Verwendung. In der Regel erfolgt diese im Rahmen eines Webservices. PredictionIO erlaubt aber auch die Integration in Mobile-Apps. Der Webdienst oder die App senden ihre Ereignisdaten an den PredictionIO-Server. Hier erfolgt die Speicherung der Daten und die Verarbeitung in der nach den Benutzerwünschen definierten Engine. Die gesendeten Daten lassen sich als Trainingsdaten für das Modell verwenden. Das Vorhersage-Ergebnis sendet der Server dann zurück an den Webdienst oder die App.
Für die Durchführung der Integration unterstützt PredictionIO die beliebtesten und am weitesten verbreiteten SDKs auf dem Markt. Dazu gehören passende Entwicklungsumgebungen für Java und Android, PHP, Python und Ruby sowie mehrere von der Entwickler-Community bereute SDKs.
Evaluation und Verbesserung
Mit dem PredictionIO Evaluationsmodul ist es möglich, die Parametereinstellungen der Algorithmen miteinander zu vergleichen, um die statistisch beste Einstellung zu finden. Dieses Evaluationsmodul besteht aus der Engine und dem Evaluator. Die Engine umfasst hierbei die zu testenden Algorithmen und die Datenquelle, während der Evaluator die zu verwendeten Metriken beinhaltet, mit dessen Hilfe die Ergebnisse der Algorithmen quantifiziert und bewertet werden sollen.
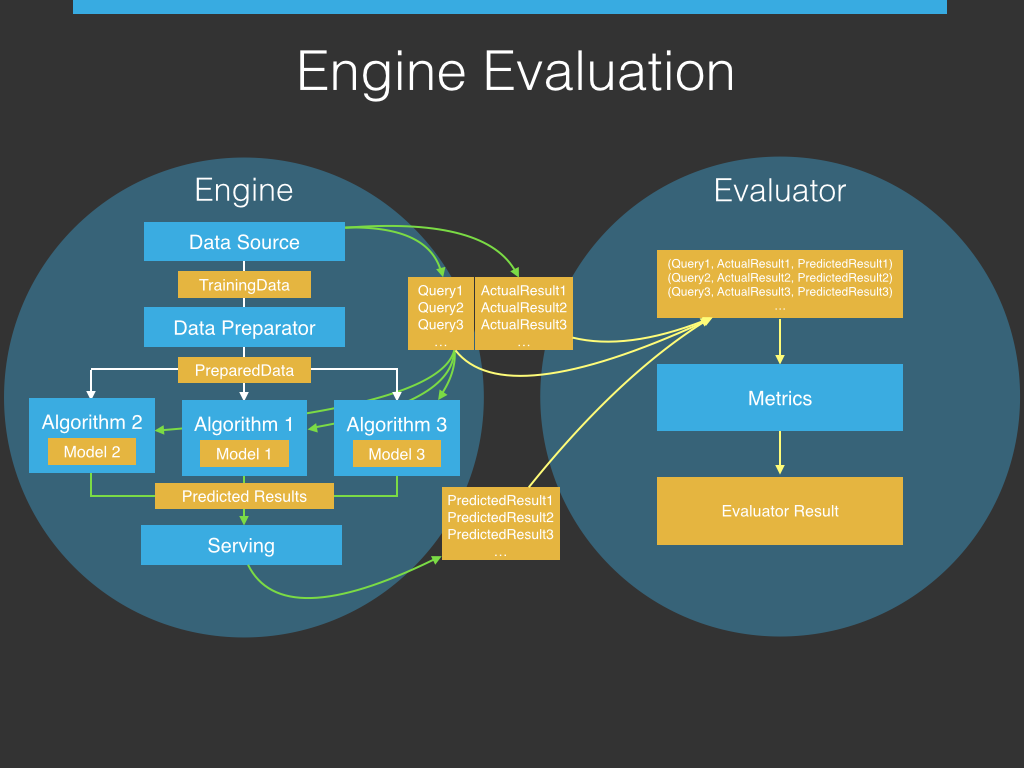
(Quelle: https://predictionio.apache.org/evaluation/)
Für den Testprozess werden Tupel bestehend aus Queries und den richtigen Ergebnissen (Actual Results) aus der Datenquelle an den Evaluator geschickt. Zusätzlich werden die Queries gegen die zu testenden Algorithmen ausgeführt, welche die erwarteten Ergebnisse (Predicted Results) zurückgeben. Diese erwarteten Ergebnisse werden nun ebenfalls an den Evaluator gesendet, welcher die Tupel, bestehend aus Queries und richtigen Ergebnissen, mit den erwarteten Ergebnissen zusammenfügt. Die Bewertung findet innerhalb des Evaluators anhand von Metriken statt, wie beispielsweise der Genauigkeit der erwarteten Ergebnisse, wobei Genauigkeit definiert ist, als der prozentuale Anteil der Queries, bei denen die erwarteten Ergebnisse der Algorithmen mit den richtigen Ergebnissen übereinstimmen. Mithilfe dieses Prozesses können eingesetzte Algorithmen kontinuierlich verbessert und getestet werden, bis die optimale Parametereinstellung gefunden wird.
Die Komponenten einer Engine modularisieren
Templates bieten einen einfachen Einstieg in PredictionIO. In der Regel wünschen sich die Entwickler jedoch nach einer gewissen Zeit eine Anpassung an ihre jeweiligen Anforderungen. Um Anpassungen vornehmen zu können, muss sich der Anwender mit den verschiedenen Komponenten vertraut machen, aus denen sich eine Engine aufbaut. Diese bezeichnet der Hersteller als D-A-S-E, was für Data Source and Data Preparator, Algorithm, Serving und Evaluation Metrics steht. PredictionIO ist so ausgelegt, dass sich diese Komponenten mit geringem Aufwand modularisieren lassen. Die Module lassen sich dann nach der Definition für den Aufbau verschiedener Engines einsetzen.
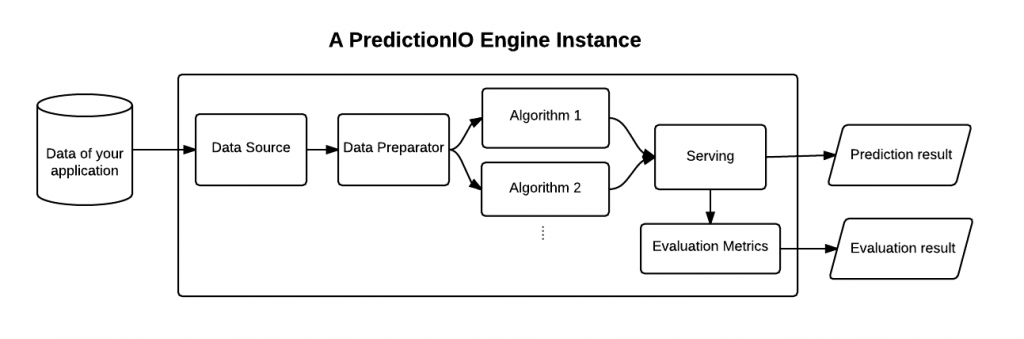
(Quelle: https://predictionio.apache.org/customize/)
Data Source liest die Daten aus der Inputquelle aus und übersetzt diese in das Wunschformat. Der Preparator prozessiert diese Daten und leitet sie weiter an den Algorithmus für das Modell-Training. Der gewählte Algorithmus wiederum entscheidet darüber, wie die Engine Vorhersagen generiert. Entscheidend ist hier zum Beispiel die Wahl der Parameter.
Die Komponente Serving bezieht sich auf die Verarbeitung von Anfragen der Webdienste oder Apps und die Weiterleitung der Vorhersage-Ergebnisse. Das Serving erlaubt die Einbindung von Unternehmens-spezifischer Logik, um die Präsentation der Ergebnisse weiter anzupassen.
Schließlich liefern die Evaluation Metrics einen numerischen Ergebniswert für die Evaluierung der Genauigkeit der getroffenen Vorhersagen. Diese Punktzahl ist nützlich, um mehrere Algorithmen miteinander zu vergleichen und mit verschiedenen Parametern, bezogen auf ihre Nützlichkeit für die Vorhersagegenauigkeit, zu experimentieren.
So erfolgt die Auswahl von Algorithmen
Jede Engine basiert auf einem Algorithmus. Mit der Auswahl dieses Algorithmus nimmt der Entwickler Einfluss auf das Vorhersagergebnis. Für jede Aufgabe eigenen sich andere Algorithmen mit anderen Parametern. Dabei kann die Engine praktisch jeden beliebigen Algorithmus für die Datenverarbeitung aufrufen. Der Aufruf erfolgt aus der Algorithm-Klasse. Algorithmen aus Spark MLlib unterstützt PredictionIO dabei nativ. Viele Templates greifen ebenfalls auf diese Klasse zurück.
Der Anwender hat die Möglichkeit, jederzeit auf einen anderen Algorithmus zu wechseln. Dazu ist es erforderlich, die Algorithmus-Klasse zu verändern. Weiterhin ist es erlaubt, mehrere Algorithmen einzusetzen. In einer einzelnen Engine lassen sich dann mehrere Modelle umsetzen. Die Ergebnisse werden von der oben beschriebenen Serving-Komponente später zusammengeführt. Mehrere Algorithmen miteinander zu kombinieren ist schwieriger, als nur auf einen Algorithmus zu setzen. Für fortgeschrittene Anwender ergeben sich hier aber viele interessante Optionen.
Außerdem ist es jederzeit möglich, seine eigenen Algorithmen in die Engine einzubinden. Diese Methode ist ebenfalls für fortgeschrittene Anwender vorgesehen und erlaubt einen noch umfassenderen Einsatz der Engine. Die Einbindung eigener Algorithmen ist ideal für Unternehmen, die in der Vergangenheit bereits Algorithmen passend für die eigenen Bedürfnisse geschrieben haben und diese nun in PredictionIO weiterverwenden möchten.
Quellen
[1] “PredictionIO Web Page.” [Online]. Available: https://predictionio.apache.org/.



{kind=link}